Descriptive Data Analysis
Contents
Descriptive Data Analysis#
기술적 데이터 분석
# 경고 메시지 출력 끄기
import warnings
warnings.filterwarnings(action='ignore')
# 노트북 셀 표시를 브라우저 전체 폭 사용하기
from IPython.core.display import display, HTML
display(HTML("<style>.container { width:100% !important; }</style>"))
from IPython.display import clear_output
%matplotlib inline
import matplotlib.pyplot as plt
import os, sys, shutil, functools
import collections, pathlib, re, string
rseed = 22
import random
random.seed(rseed)
import numpy as np
np.random.seed(rseed)
np.set_printoptions(precision=5)
np.set_printoptions(formatter={'float_kind': "{:.5f}".format})
import pandas as pd
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
pd.set_option('display.max_colwidth', None)
pd.options.display.float_format = '{:,.5f}'.format
import scipy as sp
import seaborn as sns
from pydataset import data
print(f"python ver={sys.version}")
print(f"pandas ver={pd.__version__}")
print(f"numpy ver={np.__version__}")
print(f"scipy ver={sp.__version__}")
python ver=3.8.9 (default, Jun 12 2021, 23:47:44)
[Clang 12.0.5 (clang-1205.0.22.9)]
pandas ver=1.2.4
numpy ver=1.23.1
scipy ver=1.9.0
# Iris 데이터 셋의 컬럼 정보 살피기
df_iris = data('iris')
df_iris.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 150 entries, 1 to 150
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Sepal.Length 150 non-null float64
1 Sepal.Width 150 non-null float64
2 Petal.Length 150 non-null float64
3 Petal.Width 150 non-null float64
4 Species 150 non-null object
dtypes: float64(4), object(1)
memory usage: 7.0+ KB
df_iris.head()
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | Species | |
|---|---|---|---|---|---|
| 1 | 5.10000 | 3.50000 | 1.40000 | 0.20000 | setosa |
| 2 | 4.90000 | 3.00000 | 1.40000 | 0.20000 | setosa |
| 3 | 4.70000 | 3.20000 | 1.30000 | 0.20000 | setosa |
| 4 | 4.60000 | 3.10000 | 1.50000 | 0.20000 | setosa |
| 5 | 5.00000 | 3.60000 | 1.40000 | 0.20000 | setosa |
# describe()을 통한 대략적인 데이터의 통계량 알아보기
df_iris.describe(include='all')
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | Species | |
|---|---|---|---|---|---|
| count | 150.00000 | 150.00000 | 150.00000 | 150.00000 | 150 |
| unique | NaN | NaN | NaN | NaN | 3 |
| top | NaN | NaN | NaN | NaN | versicolor |
| freq | NaN | NaN | NaN | NaN | 50 |
| mean | 5.84333 | 3.05733 | 3.75800 | 1.19933 | NaN |
| std | 0.82807 | 0.43587 | 1.76530 | 0.76224 | NaN |
| min | 4.30000 | 2.00000 | 1.00000 | 0.10000 | NaN |
| 25% | 5.10000 | 2.80000 | 1.60000 | 0.30000 | NaN |
| 50% | 5.80000 | 3.00000 | 4.35000 | 1.30000 | NaN |
| 75% | 6.40000 | 3.30000 | 5.10000 | 1.80000 | NaN |
| max | 7.90000 | 4.40000 | 6.90000 | 2.50000 | NaN |
대표값#
데이터 분석을 위해서 데이터 특성을 이해하기 위해서는 데이터의 특성을 나타내는 몇몇 통계량을 구해봄으로써 데이터를 전체적으로 빠르게 파악해 볼수 있습니다.
일반적으로 많이 쓰이는 대표값은 평균값(Average), 중앙값(Median), 최빈값(Mode) 입니다.
평균값: 평균의 데이터의 중심을 나타내는 대표값으로 사용됩니다. 평균의 종류에는 산술평균, 가중평균, 조화평균, 기하평균 등 많은 평균의 종류가 있지만 간단하게 산술평균을 많이 사용합니다.
중앙값: 중앙값은 데이터를 작은 순서로 나열했을때 중앙에 위치하는 값입니다. 데이터에 이상치(큰 값)가 포함되어 있더라도 강건(Robust, 값이 크게 흔들리지 않음)합니다. 데이터의 갯수가 짝수일 경우 중앙 값은 중앙 두 데이터의 평균을 사용합니다.
최빈값: 데이터를 계층으로 나누어 빈도수를 측정하였을때 그 빈도수가 가장 많은 값입니다.
만약, 데이터에 이상치가 포함되어 있지 않고, 데이터의 분포가 치우치지 않았다면, 평균값, 중앙값, 최빈값 모두는 비슷한 위치에 존재하게 됩니다. 이때는 통계적으로 다루기 쉬운 평균값을 대표값으로 사용하는 것이 일반 적입니다.
데이터가 이상치를 포함하고 있다면 평균값은 이상치에 민감하기 때문에 3가지 대표값이 서로 다룬 위치에 존재하게 됩니다. 이 경우 데이터의 도메인 특성에 따라 이상치를 제거하는 등의 방법을 통해 평균을 대표값으로 사용할 수 있습니다.

https://www.r-bloggers.com/2020/11/skewness-and-kurtosis-in-statistics/
@최빈값의 활용: 과거 대칭방식의 암호해독시에 문서상에서 나타나는 알파벳의 최빈값과 암호화된 알파멧의 최빈값을 비교하여 해독의 기준점으로 많이 사용하였다고 합니다.
# 평균값
df_iris.mean()
Sepal.Length 5.84333
Sepal.Width 3.05733
Petal.Length 3.75800
Petal.Width 1.19933
dtype: float64
# 중앙값
df_iris.median()
Sepal.Length 5.80000
Sepal.Width 3.00000
Petal.Length 4.35000
Petal.Width 1.30000
dtype: float64
# 최빈값
df_iris.mode()
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | Species | |
|---|---|---|---|---|---|
| 0 | 5.00000 | 3.00000 | 1.40000 | 0.20000 | setosa |
| 1 | NaN | NaN | 1.50000 | NaN | versicolor |
| 2 | NaN | NaN | NaN | NaN | virginica |
그외 알아보면 평균들: 산술평균, 기하평균, 조화평균, 등등
데이터의 분산#
산포도(Dispersion)
산포도는 데이터의 흩어짐 정도를 나타냅니다. 같은 데이터의 대표값을 가지더라도 데이터의 산포도는 다를 수 있기 때문에 대표값과 더불어 데이터의 특성을 파악하는데 중요하게 사용됩니다.
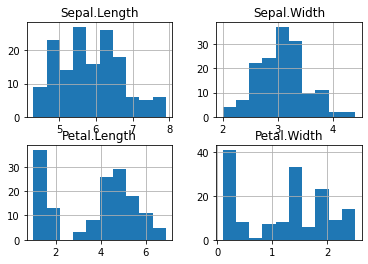
히스토그램(Histogram)#
데이터의 분포를 히스토그램을 통해 시각적으로 확인해 볼 수 있습니다.
df_iris.hist(bins=10, grid=True)
array([[<AxesSubplot:title={'center':'Sepal.Length'}>,
<AxesSubplot:title={'center':'Sepal.Width'}>],
[<AxesSubplot:title={'center':'Petal.Length'}>,
<AxesSubplot:title={'center':'Petal.Width'}>]], dtype=object)
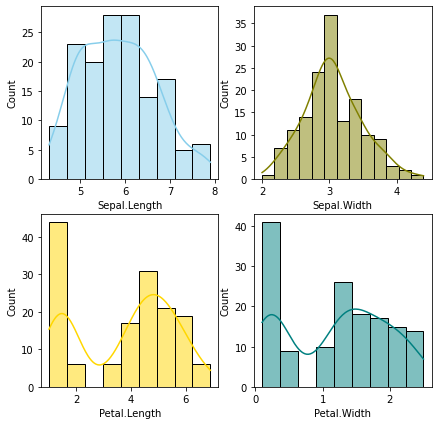
fig, axs = plt.subplots(2, 2, figsize=(7, 7))
sns.histplot(data=df_iris, x="Sepal.Length", kde=True, color="skyblue", ax=axs[0, 0])
sns.histplot(data=df_iris, x="Sepal.Width", kde=True, color="olive", ax=axs[0, 1])
sns.histplot(data=df_iris, x="Petal.Length", kde=True, color="gold", ax=axs[1, 0])
sns.histplot(data=df_iris, x="Petal.Width", kde=True, color="teal", ax=axs[1, 1])
plt.show()
사분위수(Quartile)#
데이터를 정렬하면 최소값(Min), 최대값(Max), 범위(Range)를 알 수 있으며 대표 값 중에 하나인 중앙값(Median)을 통해 데이터 범위 내에 주요 데이터들의 위치를 알 수 있습니다.
데이터의 분포를 파악하기 위해 데이터를 4등분하여 보는 것은 의미가 있기 때문에 데이터를 4등분하여 나타낸 것을 사분위수(Quartile)라고 합니다. 여기서 각 4등분 위치를 1사분위수(Q1), 2사분위수(Q2=중앙값), 3사분위수(Q3)로 나타내며 1사분위수에서 3사분위수까지를 사분범위(Interquartile Range)라고 합니다.
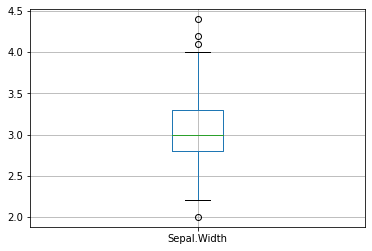
숫자로는 직관적으로 분포를 파악하기 힘들기 때문에 상자수염그림(Boxplot)을 사용하여 시각화하여 판단합니다.
# 사분위수
q1 = df_iris['Sepal.Width'].quantile(.25)
q2 = df_iris['Sepal.Width'].quantile(.5)
q3 = df_iris['Sepal.Width'].quantile(.75)
iqr = q3 - q1
print(f"Q1: {q1}, Q2: {q2}, Q3: {q3}, IQR: {iqr:.2f}")
Q1: 2.8, Q2: 3.0, Q3: 3.3, IQR: 0.50
# Boxplot를 이용한 시각화
df_iris.boxplot(column='Sepal.Width')
plt.title('')
Text(0.5, 1.0, '')
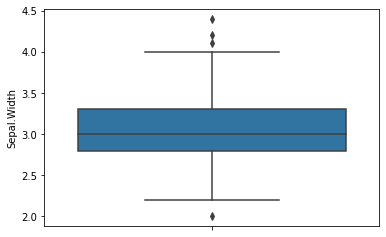
# Seaborn를 이용한 Boxplot 시각화
sns.boxplot(y='Sepal.Width', data=df_iris)
<AxesSubplot:ylabel='Sepal.Width'>
# Boxplot를 이용한 시각화
df_iris.boxplot(column='Petal.Length', by='Species')
plt.title('')
Text(0.5, 1.0, '')
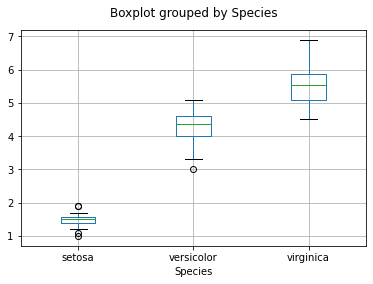
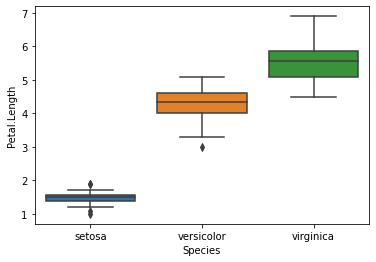
# Seaborn를 이용한 Boxplot 시각화
sns.boxplot(x='Species', y='Petal.Length', data=df_iris)
<AxesSubplot:xlabel='Species', ylabel='Petal.Length'>
분산(Variance), 표준편차(Standard Deviation)#
분산과 표준편차는 평균값을 이용해 산포도를 수치화 할 수 있으며, 통계 계산시에도 평균값과 함께 사용하기 유용합니다.
편차(Deviation): 데이터가 평균으로부터 떨어진 정도, 데이터 - 평균
분산(Variance): 편차 제곱의 평균, 편차의 평균은 항상 0 이 되기 때문에 분산을 이용함
표준편차(Standard Deviation): 분산의 제곱근, 분산은 제곱값으로 수가 너무 크고, 단위가 변하기(예, \(m\) -> \(m^2\))때문에 표준편차를 이용함

# 분산
df_iris.var()
Sepal.Length 0.68569
Sepal.Width 0.18998
Petal.Length 3.11628
Petal.Width 0.58101
dtype: float64
# 표준편차
df_iris.std()
Sepal.Length 0.82807
Sepal.Width 0.43587
Petal.Length 1.76530
Petal.Width 0.76224
dtype: float64
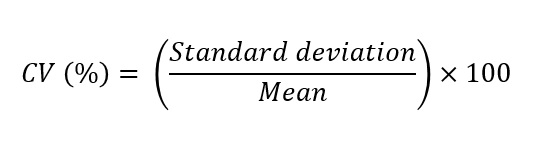
변동계수(Coefficient of Variation)#
변동계수(CV)는 표준편차를 평균으로 나눈 값으로 두 집단에서 데이터의 흩어짐 정도를 비교하는데 사용합니다.
예를 들어 두 회사의 연도별 수익률에 대하여 어느 회사가 변동폭이 큰지를 비교할때 사용해볼 수 있습니다.
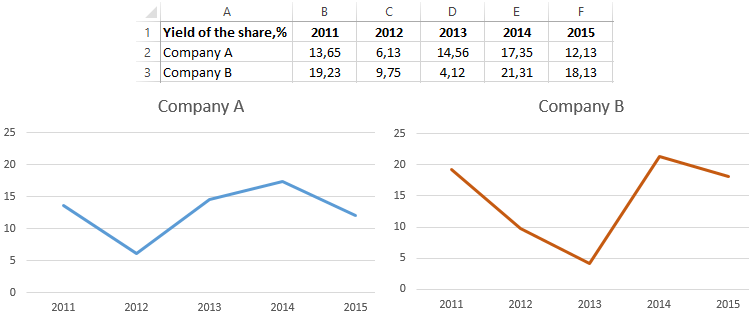
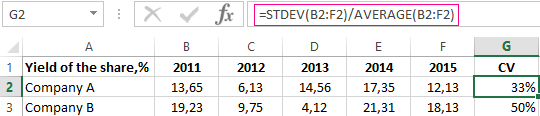
https://exceltable.com/en/analyses-reports/coefficient-variation-in-excel
# Scipy 를 통한 CV 계산
# https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.variation.html
mean1 = df_iris['Sepal.Length'].mean()
mean2 = df_iris['Petal.Length'].mean()
cv1 = sp.stats.variation(df_iris['Sepal.Length'])
cv2 = sp.stats.variation(df_iris['Petal.Length'])
print(f"mean1: {mean1:.2f}, mean2: {mean2:.2f}")
print(f"cv1: {cv1:.2f}, cv2: {cv2:.2f}")
mean1: 5.84, mean2: 3.76
cv1: 0.14, cv2: 0.47