Ensemble Classification
Contents
Ensemble Classification#
앙상블 기법은 모델의 예측 성능을 높이기 위해 여러 개의 기본 모델들의 결과를 조합하여 사용하는 방식입니다. 선형/비선형 데이터셋 및 분류/회귀 문제 모두에 사용할수 있습니다.
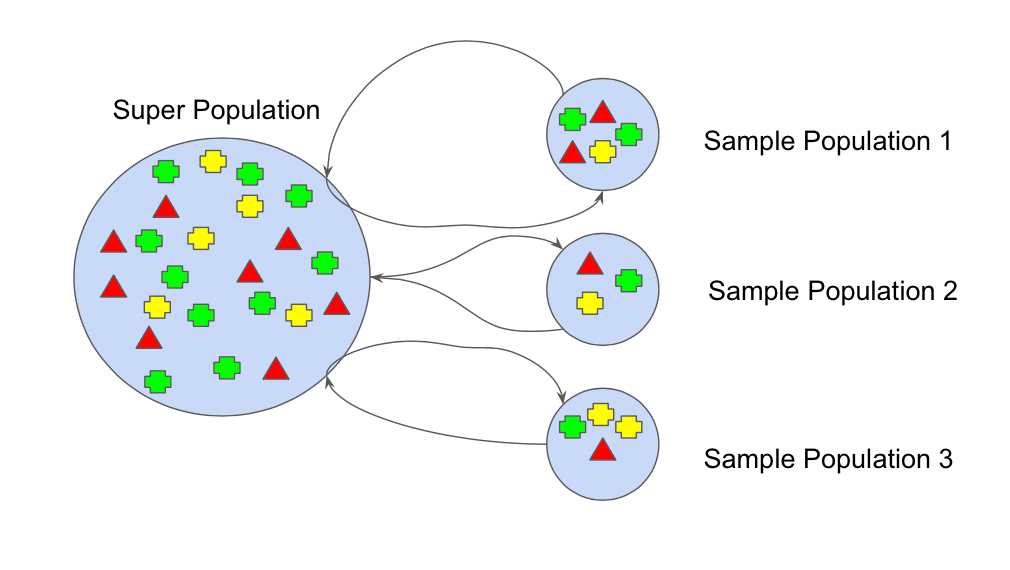
앙상블 기법에서 모델을 학습시키기 위해 학습 데이터 셋을 구성하는 방식으로 Bootstrapping 방식을 사용합니다. 이는 흔히 말하는 ‘랜덤 복원 샘플링’입니다. 샘플에서 랜덤 복원 샘플을 통해 리샘플링한 다양한 학습 데이터 셋을 구성함으로써 아래 그림 처럼 전체적으로 평균, 분산 등의 통계적 특성은 같은 샘플이어도 그 안에 속한 샘플들은 각각 다양한 특성을 포함하도록 하여 강건한 모델을 학습시키는데 도움이 되도록 합니다.
Bootstrapping:
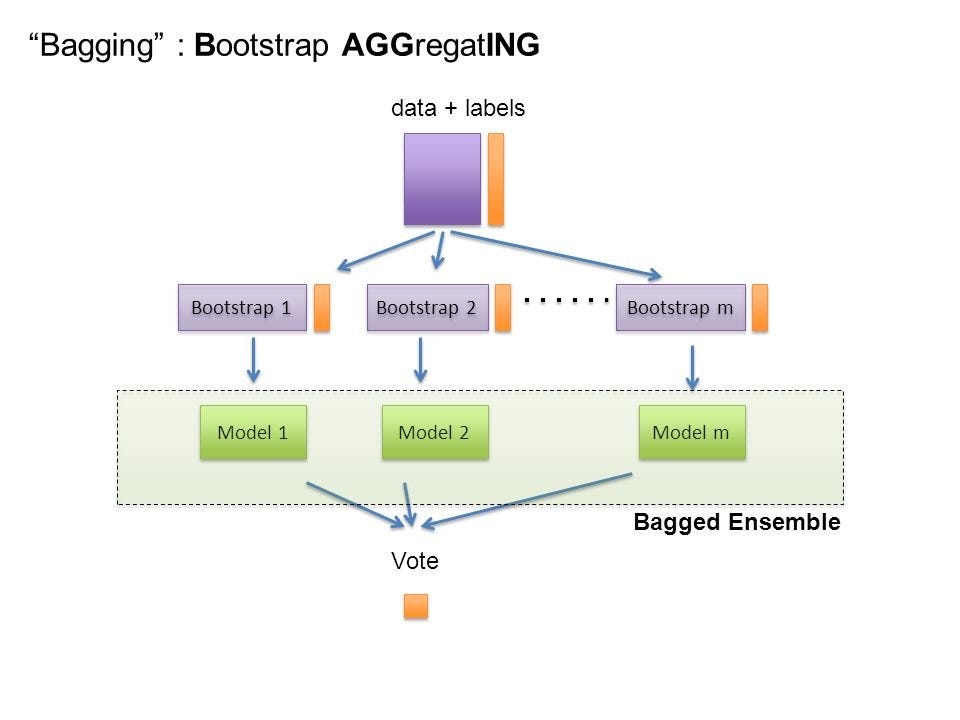
Bagging methods#
데이터를 Bootstrapping 하여 만든 학습 데이터 셋에 대하여 각각 독립적인 모델을 학습 시킨 후, 각 모델이 예측 한 값의 평균(Average, 연속형 변수) 또는 다수 투표(Majority Voting, 범주형 변수)방식을 통한 Bootstrap Aggregating하여 예측하는 방식 (복수의 독립적인 모델을 사용하는 방식이기에 분산처리 가능하여 학습 속도가 빠름)
예: Random Forest, …
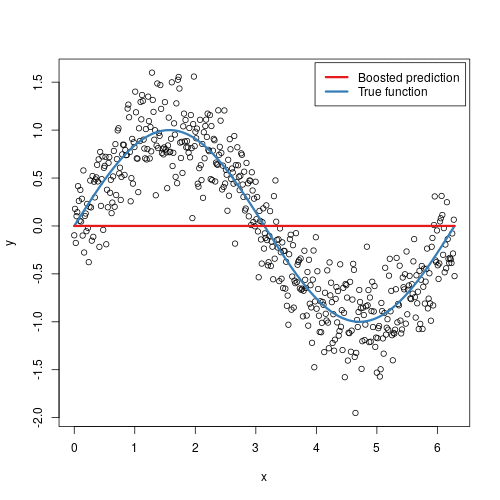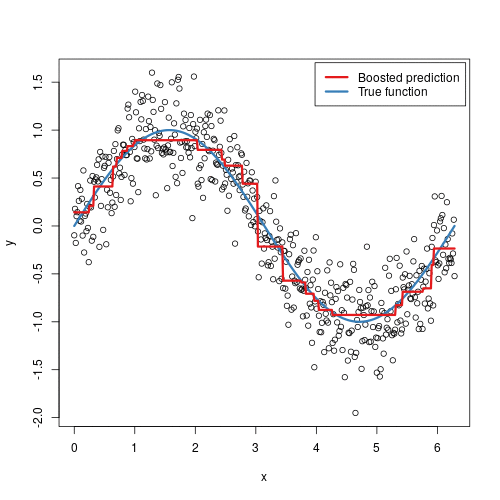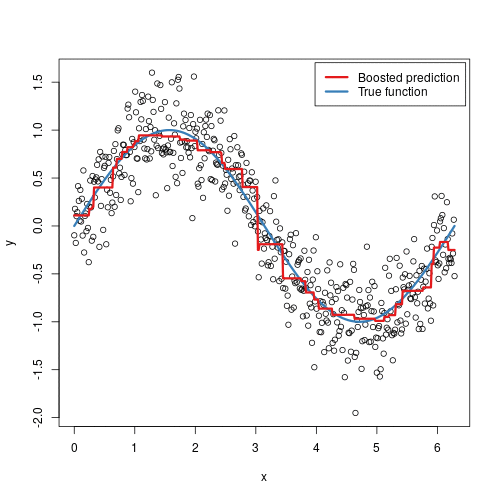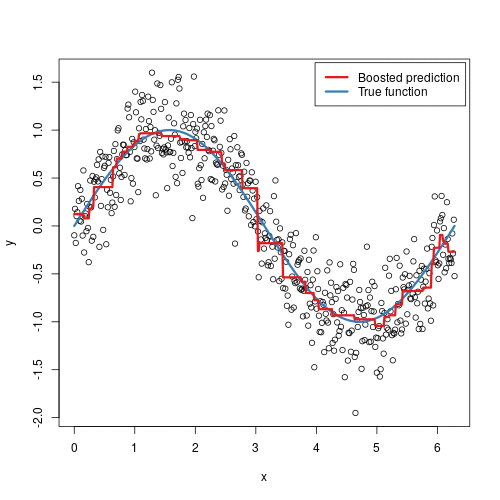
Boosting methods#
약한 학습기(weak learner)을 학습 시키고, 예측 오류를 최소화 하기위해 약한 학습기(weak learner)를 추가하는 식의 순차적 학습 방식을 통해 강한 학습기(strong learner)를 만드는 방법 (순차적으로 학습을 진행하는 방식으로 분산처리가 불가능하여 학습 속도가 느림)
예: AdaBoost, XGBoost, GradientBoost, …
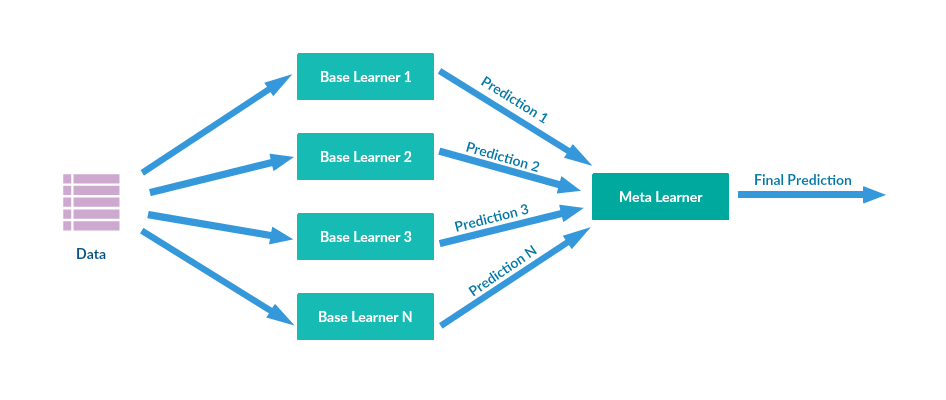
Stacking methods#
모델링 알고리즘(SVM, RandomForest, XGBoost, …)들은 각기 다른 장단점을 가지기 때문에 서로 다른 모델링 알고리즘을 조합해서 최고의 성능을 내는 모델을 생성하는 방법
예: StackNet, …
# 경고 메시지 출력 끄기
import warnings
warnings.filterwarnings(action='ignore')
%matplotlib inline
import matplotlib.pyplot as plt
import IPython
import platform, sys
rseed = 22
import random
random.seed(rseed)
import numpy as np
np.random.seed(rseed)
np.set_printoptions(precision=3)
np.set_printoptions(formatter={'float_kind': "{:.3f}".format})
import pandas as pd
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
pd.set_option('display.max_colwidth', None)
pd.options.display.float_format = '{:,.5f}'.format
import sklearn
print(f"python ver={sys.version}")
print(f"python platform={platform.architecture()}")
print(f"pandas ver={pd.__version__}")
print(f"numpy ver={np.__version__}")
print(f"sklearn ver={sklearn.__version__}")
python ver=3.8.9 (default, Jun 12 2021, 23:47:44)
[Clang 12.0.5 (clang-1205.0.22.9)]
python platform=('64bit', '')
pandas ver=1.2.4
numpy ver=1.19.5
sklearn ver=0.24.2
import xgboost as xgb
from sklearn import datasets, model_selection, ensemble, metrics
# 데이터
n_samples = 10000
xs, ys = datasets.make_classification(
n_samples=n_samples, # 데이터 수
n_features=10, # X feature 수
n_informative=3,
n_classes=3, # Y class 수
random_state=rseed) # 난수 발생용 Seed 값
print(f"data shape: xs={xs.shape}, ys={ys.shape}")
train_xs, test_xs, train_ys, test_ys = model_selection.train_test_split(
xs, ys, test_size=0.3, shuffle=True, random_state=rseed)
print(f"train shape: train_xs={train_xs.shape}, train_ys={train_ys.shape}")
print(f"test shape: test_xs={test_xs.shape}, test_ys={test_ys.shape}")
# 모델
models = [
ensemble.BaggingClassifier(),
ensemble.RandomForestClassifier(),
ensemble.AdaBoostClassifier(),
ensemble.GradientBoostingClassifier(),
xgb.XGBClassifier()
]
for model in models:
# 학습
print(f"\nmodel={model}")
model.fit(train_xs, train_ys)
# 평가
pred_ys = model.predict(test_xs)
acc = metrics.accuracy_score(test_ys, pred_ys)
print(f"acc={acc:.5f}")
cr = metrics.classification_report(test_ys, pred_ys)
print(f"classification_report\n{cr}")
try:
feature_importances = model.feature_importances_
print(f"Feature Importances: {feature_importances}")
plt.bar(range(len(feature_importances)), feature_importances)
plt.title("Feature Importances")
plt.show()
except:
pass
data shape: xs=(10000, 10), ys=(10000,)
train shape: train_xs=(7000, 10), train_ys=(7000,)
test shape: test_xs=(3000, 10), test_ys=(3000,)
model=BaggingClassifier()
acc=0.88667
classification_report
precision recall f1-score support
0 0.91 0.92 0.92 968
1 0.83 0.89 0.86 981
2 0.93 0.85 0.89 1051
accuracy 0.89 3000
macro avg 0.89 0.89 0.89 3000
weighted avg 0.89 0.89 0.89 3000
model=RandomForestClassifier()
acc=0.90067
classification_report
precision recall f1-score support
0 0.93 0.92 0.93 968
1 0.84 0.92 0.88 981
2 0.94 0.86 0.90 1051
accuracy 0.90 3000
macro avg 0.90 0.90 0.90 3000
weighted avg 0.90 0.90 0.90 3000
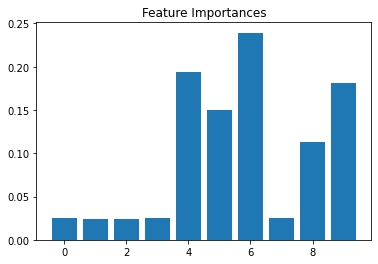
Feature Importances: [0.024 0.025 0.023 0.024 0.197 0.127 0.235 0.024 0.158 0.164]
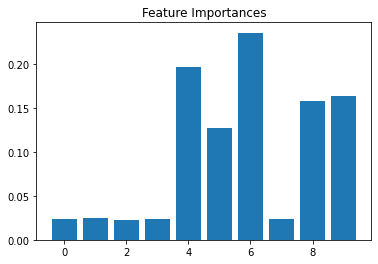
model=AdaBoostClassifier()
acc=0.81467
classification_report
precision recall f1-score support
0 0.89 0.76 0.82 968
1 0.71 0.84 0.77 981
2 0.87 0.85 0.86 1051
accuracy 0.81 3000
macro avg 0.82 0.81 0.82 3000
weighted avg 0.83 0.81 0.82 3000
Feature Importances: [0.000 0.020 0.000 0.060 0.240 0.180 0.160 0.020 0.160 0.160]
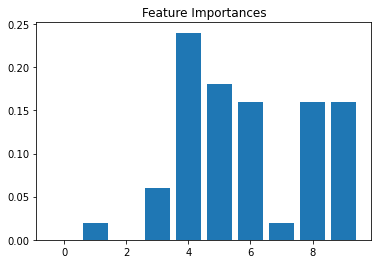
model=GradientBoostingClassifier()
acc=0.88200
classification_report
precision recall f1-score support
0 0.91 0.90 0.91 968
1 0.81 0.89 0.85 981
2 0.93 0.85 0.89 1051
accuracy 0.88 3000
macro avg 0.88 0.88 0.88 3000
weighted avg 0.89 0.88 0.88 3000
Feature Importances: [0.002 0.001 0.001 0.001 0.231 0.143 0.334 0.002 0.084 0.199]
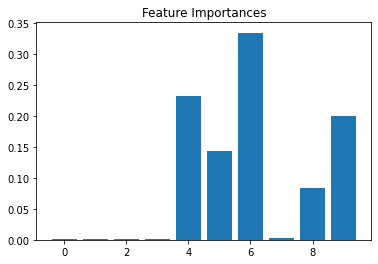
model=XGBClassifier(base_score=None, booster=None, colsample_bylevel=None,
colsample_bynode=None, colsample_bytree=None,
enable_categorical=False, gamma=None, gpu_id=None,
importance_type=None, interaction_constraints=None,
learning_rate=None, max_delta_step=None, max_depth=None,
min_child_weight=None, missing=nan, monotone_constraints=None,
n_estimators=100, n_jobs=None, num_parallel_tree=None,
predictor=None, random_state=None, reg_alpha=None,
reg_lambda=None, scale_pos_weight=None, subsample=None,
tree_method=None, validate_parameters=None, verbosity=None)
[07:22:50] WARNING: /Users/runner/work/xgboost/xgboost/src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'multi:softprob' was changed from 'merror' to 'mlogloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
acc=0.88967
classification_report
precision recall f1-score support
0 0.92 0.92 0.92 968
1 0.83 0.90 0.86 981
2 0.93 0.85 0.89 1051
accuracy 0.89 3000
macro avg 0.89 0.89 0.89 3000
weighted avg 0.89 0.89 0.89 3000
Feature Importances: [0.025 0.024 0.024 0.025 0.194 0.150 0.239 0.025 0.113 0.181]