Train/Valid/Test Dataset
Contents
Train/Valid/Test Dataset#
머신러닝은 주어진 데이터 셋에서 독립변수와 종속변수의 상관관계를 잘 나타낼 수 있는 모델을 학습을 통해서 생성하는 작업입니다. 따라서, 데이터 셋은 머신러닝에서 매우 중요한 요소이며, “Garbage In, Garbage Out” 이라는 말로 대표되고 있습니다.
머신러닝에서 학습을 위한 데이터 셋을 준비하는데 중요한 것은
준비한 전체 학습 데이터 셋이 모집단을 대표할 수 있어야 하며
분리한 Train/Test 셋 사이에 데이터 오염이 없어야 하고
분리된 Train/Test 셋 또한 모집단을 대표할 수 있어야 한다.
입니다. 데이터 셋이 모집단을 대표할 수 있어야 한다는 가정은 큰 수 이상의 랜덤 샘플을 통해 해결이 가능하지만, 데이터의 도메인에 따라 무작정 랜덤 샘플을 할수 없는 경우에는 도메인에 맞는 샘플링 방법을 통해 데이터를 확보해야 합니다. (예를 들어 시계열 데이터의 경우는 데이터 오염을 없애기 위해 시간 범위로 학습 데이터를 분리합니다.) 정해진 Train과 Test를 나누는 비율은 없지만, 보통 7:3, 8:2 정도의 비율을 통해 학습 데이터를 분리합니다.
# 경고 메시지 출력 끄기
import warnings
warnings.filterwarnings(action='ignore')
%matplotlib inline
import matplotlib.pyplot as plt
import IPython
import sys
rseed = 22
import random
random.seed(rseed)
import numpy as np
np.random.seed(rseed)
np.set_printoptions(precision=3)
np.set_printoptions(formatter={'float_kind': "{:.3f}".format})
import pandas as pd
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
pd.set_option('display.max_colwidth', None)
pd.options.display.float_format = '{:,.5f}'.format
import sklearn
print(f"python ver={sys.version}")
print(f"pandas ver={pd.__version__}")
print(f"numpy ver={np.__version__}")
print(f"sklearn ver={sklearn.__version__}")
python ver=3.8.9 (default, Jun 12 2021, 23:47:44)
[Clang 12.0.5 (clang-1205.0.22.9)]
pandas ver=1.2.4
numpy ver=1.19.5
sklearn ver=0.24.2
from sklearn import datasets, model_selection
# 데이터 생성
n_samples = 100
xs, ys = datasets.make_classification(n_samples=n_samples, n_features=5, random_state=rseed)
print(f"data shape: xs={xs.shape}, ys={ys.shape}")
# 7:3 비율로 랜덤 샘플하여 Train/Test 셋 분리
train_xs, test_xs, train_ys, test_ys = model_selection.train_test_split(
xs, ys, test_size=0.3, shuffle=True, random_state=rseed)
print(f"train shape: train_xs={train_xs.shape}, train_ys={train_ys.shape}")
print(f"test shape: test_xs={test_xs.shape}, test_ys={test_ys.shape}")
data shape: xs=(100, 5), ys=(100,)
train shape: train_xs=(70, 5), train_ys=(70,)
test shape: test_xs=(30, 5), test_ys=(30,)
Overfitting#
모델은 학습을 통해 Train 데이터 셋을 잘 설명할 수 있는 최적화를 하게 됩니다. 하지만, 과도한 최적화는 새로운 데이터에 대한 적응성을 떨어 트리게 되어, 모델이 실제 배포 된 후, 오히려 제대로 된 성능을 내지 못하게 됩니다.
Underfit(과소적합) 상태는 모델이 데이터 셋을 잘 설명하지 못하는 상태이며, Overfit(과적합) 상태는 모델이 너무 학습 데이터에 최적화되어 새로운 데이터에 대한 적응성이 떨어지는 상태 입니다.
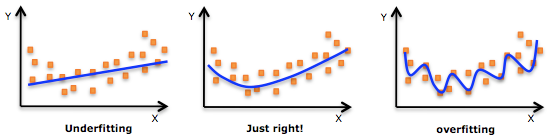
Underfit은 모델 변경, 파라미터 최적화, Regularization(정규화) 제약을 줄이는 방향으로 해결 가능하며, Overfit의 경우에는 Early Stop 정책을 통한 학습 제한 및 정규화 제약을 높이는 방향으로 해결 가능합니다.
Cross Validation Score#
머신러닝 학습 과정에서 과적합을 방지하기 위해 Train 셋을 다시 Train/Valid 셋을 나누고, Valid 셋을 이용하여 학습 중 평가를 진행 하면서 학습이 잘 진행되고 있는지, 그리고 과적합이 일어나지 않는지 체크하고 과적합 전에 일찍 학습을 종료하는 Early Stop 정책을 사용하는 경우가 많습니다. Train 셋이 충분하다면 Test 셋을 나누었던 비율과 비슷한 7:3, 8:2 비율로 Valid 셋을 나누어 진행하면 되지만, Train 셋이 충분하지 않을 경우 Valid 셋을 확습시 활용할 수 없는 문제가 발생하게 됩니다. 이런 문제를 방지하기 위해서, Valid 셋을 누락 시키지 않고, 학습시 사용하기 위한 여러 교차 검증 방법이 존재 합니다.

Scikit-learn 에서는 교차 방법을 통해 나누어진 데이터 셋을 이용하여 학습과 평가를 한번에 진행 할 수 있도록 유용한 함수를 제공하고 있습니다.
평가를 위해 제공되는 Scoring 함수는 아래 링크에서 확인 할 수 있습니다.
sklearn.metrics 에서 제공되는 함수들은
_score 로 끝나는 함수들은 높은 값이 좋은 것입니다.
_error or _loss 로 끝나는 함수들은 낮은 값이 좋은 것입니다. (make_scorer 사용시 bigger_is_better = False로 설정하세요, 기본 값은 True입니다.)
Regression#
평가 함수를 사용할 때 주의할 점은 Cross Validation Score는 높은 값이 좋은 것으로 설계되어 있습니다.
Regression 의 에러 함수는 평가 함수의 Nagative 값을 넣어주어야 제대로 동작합니다. 그리고, 스코어 값을 다시 에러 함수로 평가할때는 본연의 의미대로 바꾸기 위해 다시 ‘-‘ 를 붙여 환원합니다.
from sklearn import datasets, model_selection, linear_model, metrics
# 데이터
n_samples = 1000
xs, ys = datasets.make_regression(
n_samples=n_samples, # 데이터 수
n_features=1, # X feature 수
bias=1.0, # Y 절편
noise=0.3, # X 변수들에 더해지는 잡음의 표준 편차
random_state=rseed) # 난수 발생용 Seed 값
print(f"data shape: xs={xs.shape}, ys={ys.shape}")
train_xs, test_xs, train_ys, test_ys = model_selection.train_test_split(
xs, ys, test_size=0.3, shuffle=True, random_state=rseed)
print(f"train shape: train_xs={train_xs.shape}, train_ys={train_ys.shape}")
print(f"test shape: test_xs={test_xs.shape}, test_ys={test_ys.shape}")
plt.scatter(train_xs, train_ys, label='train', c='b')
plt.scatter(test_xs, test_ys, label='test', c='g')
plt.legend()
plt.show()
model = linear_model.LinearRegression()
# 평가 함수를 사용할 때 주의할 점은 Cross Validation Score는 높은 값이 좋은 것으로 설계되어 있습니다.
# scoring 값으로 Regression 의 에러 함수를 사용할때는 Nagative 값을 넣어주어야 제대로 동작합니다.
# negative 로 바꾸는 것이 직관적이지 않다면 에러함수 대신에 r2 값을 사용할 수도 있습니다.
# cv 파라미터에 숫자를 사용하면 기본적으로 KFold 방식으로 교차검증을 합니다.
scores = model_selection.cross_val_score(model, train_xs, train_ys,
cv=5,
scoring='neg_mean_squared_error') # 또는 scoring='r2'
# 특정 교차검증 방식을 사용하기 위해서는 해당 인스턴스를 파라미터로 넘겨주면 됩니다.
cv = model_selection.KFold(n_splits=5)
scores = model_selection.cross_val_score(model, train_xs, train_ys,
cv=cv,
scoring='neg_mean_squared_error')
# 그리고, 스코어 값을 다시 에러 함수로 평가할때는 본연의 의미대로 바꾸기 위해 다시 '-' 를 붙여 환원합니다.
rmse_scores = np.sqrt(-scores)
print("RMSE Scores: {}, Mean: {:.3f}, STD: {:.3f}".format(rmse_scores, rmse_scores.mean(), rmse_scores.std()))
data shape: xs=(1000, 1), ys=(1000,)
train shape: train_xs=(700, 1), train_ys=(700,)
test shape: test_xs=(300, 1), test_ys=(300,)
RMSE Scores: [0.266 0.284 0.315 0.289 0.259], Mean: 0.283, STD: 0.020
Classification#
Classification 의 scoring 함수는 보통 accuracy 또는 f1_score를 사용합니다. 멀티 클래스 분류의 경우 f1_score 계산시 학습 데이터를 고려하여 ‘macro’, ‘wegithed’, ‘micro’, ‘samples’ 옵션으로 구할 수 있습니다.(Classification)
from sklearn import datasets, model_selection, ensemble, metrics
# 데이터
n_samples = 10000
xs, ys = datasets.make_classification(
n_samples=n_samples, # 데이터 수
n_features=10, # X feature 수
n_informative=3,
n_classes=3, # Y class 수
random_state=rseed) # 난수 발생용 Seed 값
print(f"data shape: xs={xs.shape}, ys={ys.shape}")
train_xs, test_xs, train_ys, test_ys = model_selection.train_test_split(
xs, ys, test_size=0.3, shuffle=True, random_state=2)
print(f"train shape: train_xs={train_xs.shape}, train_ys={train_ys.shape}")
print(f"test shape: test_xs={test_xs.shape}, test_ys={test_ys.shape}")
# 모델
model = ensemble.RandomForestClassifier()
# cv 파라미터에 숫자를 사용하면 기본적으로 KFold 방식으로 교차겁증을 합니다.
scores = model_selection.cross_val_score(model, train_xs, train_ys,
cv=5,
scoring='f1_macro')
# 특정 교차검증 방식을 사용하기 위해서는 해당 인스턴스를 파라미터로 넘겨주면 됩니다.
model_selection.StratifiedKFold(n_splits=5)
scores = model_selection.cross_val_score(model, train_xs, train_ys,
cv=cv,
scoring='f1_macro')
f1_scores = scores
print("F1 Scores: {}, Mean: {}, STD: {}".format(f1_scores, f1_scores.mean(), f1_scores.std()))
data shape: xs=(10000, 10), ys=(10000,)
train shape: train_xs=(7000, 10), train_ys=(7000,)
test shape: test_xs=(3000, 10), test_ys=(3000,)
F1 Scores: [0.896 0.897 0.890 0.885 0.883], Mean: 0.8903309119990699, STD: 0.0055643039413914245
Cross Validation#
Cross Validation Score 함수의 파라미터로 사용할수 있는 학습을 위한 다양한 교차 검증 방법을 살펴봅니다.
K-Fold#
K-fold 방법은 교차검증 방법 중에서 가장 일반적으로 사용되는 방법입니다. Train 셋을 K 개의 그룹으로 나누고 1개는 Valid 셋이 되고 나머지는 Train 셋으로 하여 모델을 반복 학습 시키는 방법입니다. Repeated K-fold 방식은 다른 랜덤 인덱스로 K-fold 를 반복하는 방법입니다. K-fold 방법은 그룹내 Class 의 균형에 대한 고려가 없이 나누는 방법이기 때문에 그룹안에 학습 데이터의 Class 가 불균형하게 들어갈 수 있습니다.
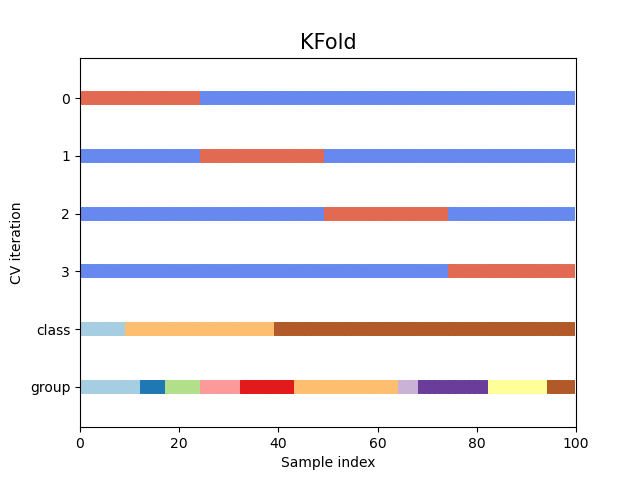
# 데이터 생성
n_samples = 10
xs, ys = datasets.make_classification(n_samples=n_samples, n_features=5, n_classes=2)
print(f"data shape: xs={xs.shape}, ys={ys.shape}")
# Cross Validation Methods
cvs = [
model_selection.KFold(n_splits=2),
model_selection.RepeatedKFold(n_splits=2, n_repeats=2)
]
for cv in cvs:
print(f"\nCross Valid: {cv}")
for idx_train, idx_valid in cv.split(xs):
print(f"idx: train: {idx_train}, valid: {idx_valid}")
train_xs, train_ys = xs[idx_train], ys[idx_train]
valid_xs, valid_ys = xs[idx_valid], ys[idx_valid]
print(f"train shape: train_xs={train_xs.shape}, train_ys={train_ys.shape}")
print(f"test shape: test_xs={test_xs.shape}, test_ys={test_ys.shape}")
data shape: xs=(10, 5), ys=(10,)
Cross Valid: KFold(n_splits=2, random_state=None, shuffle=False)
idx: train: [5 6 7 8 9], valid: [0 1 2 3 4]
train shape: train_xs=(5, 5), train_ys=(5,)
test shape: test_xs=(3000, 10), test_ys=(3000,)
idx: train: [0 1 2 3 4], valid: [5 6 7 8 9]
train shape: train_xs=(5, 5), train_ys=(5,)
test shape: test_xs=(3000, 10), test_ys=(3000,)
Cross Valid: RepeatedKFold(n_repeats=2, n_splits=2, random_state=None)
idx: train: [2 3 5 6 9], valid: [0 1 4 7 8]
train shape: train_xs=(5, 5), train_ys=(5,)
test shape: test_xs=(3000, 10), test_ys=(3000,)
idx: train: [0 1 4 7 8], valid: [2 3 5 6 9]
train shape: train_xs=(5, 5), train_ys=(5,)
test shape: test_xs=(3000, 10), test_ys=(3000,)
idx: train: [0 1 4 7 8], valid: [2 3 5 6 9]
train shape: train_xs=(5, 5), train_ys=(5,)
test shape: test_xs=(3000, 10), test_ys=(3000,)
idx: train: [2 3 5 6 9], valid: [0 1 4 7 8]
train shape: train_xs=(5, 5), train_ys=(5,)
test shape: test_xs=(3000, 10), test_ys=(3000,)
Stratified K-Fold#
Stratified K-Fold 방식은 K-Fold 와 달리 Valid 셋을 분리 할 때, Class 의 비율대로 균등하게 Valid 셋을 분리합니다.
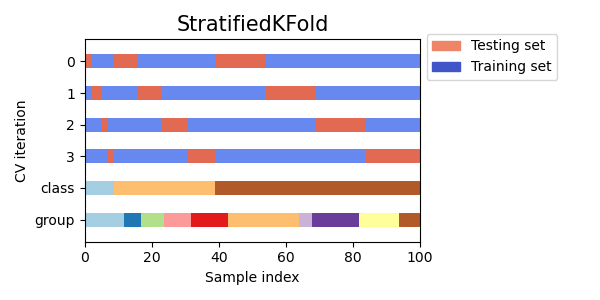
# 데이터 생성
n_samples = 10
xs, ys = datasets.make_classification(n_samples=n_samples, n_features=5, n_classes=2)
print(f"data shape: xs={xs.shape}, ys={ys.shape}")
# Cross Validation Methods
cvs = [
model_selection.StratifiedKFold(n_splits=2),
model_selection.RepeatedStratifiedKFold(n_splits=2, n_repeats=2)
]
for cv in cvs:
print(f"\nCross Valid: {cv}")
for idx_train, idx_valid in cv.split(xs, ys):
print(f"idx: train: {idx_train}, valid: {idx_valid}")
train_xs, train_ys = xs[idx_train], ys[idx_train]
valid_xs, valid_ys = xs[idx_valid], ys[idx_valid]
print(f"train shape: train_xs={train_xs.shape}, train_ys={train_ys.shape}")
print(f"valid shape: valid_xs={valid_xs.shape}, valid_ys={valid_ys.shape}")
data shape: xs=(10, 5), ys=(10,)
Cross Valid: StratifiedKFold(n_splits=2, random_state=None, shuffle=False)
idx: train: [4 6 7 8 9], valid: [0 1 2 3 5]
train shape: train_xs=(5, 5), train_ys=(5,)
valid shape: valid_xs=(5, 5), valid_ys=(5,)
idx: train: [0 1 2 3 5], valid: [4 6 7 8 9]
train shape: train_xs=(5, 5), train_ys=(5,)
valid shape: valid_xs=(5, 5), valid_ys=(5,)
Cross Valid: RepeatedStratifiedKFold(n_repeats=2, n_splits=2, random_state=None)
idx: train: [1 3 6 7 9], valid: [0 2 4 5 8]
train shape: train_xs=(5, 5), train_ys=(5,)
valid shape: valid_xs=(5, 5), valid_ys=(5,)
idx: train: [0 2 4 5 8], valid: [1 3 6 7 9]
train shape: train_xs=(5, 5), train_ys=(5,)
valid shape: valid_xs=(5, 5), valid_ys=(5,)
idx: train: [0 3 5 6 7], valid: [1 2 4 8 9]
train shape: train_xs=(5, 5), train_ys=(5,)
valid shape: valid_xs=(5, 5), valid_ys=(5,)
idx: train: [1 2 4 8 9], valid: [0 3 5 6 7]
train shape: train_xs=(5, 5), train_ys=(5,)
valid shape: valid_xs=(5, 5), valid_ys=(5,)
Group K-Fold#
Group K-Fold 방식은 Valid 셋을 나눌때 사용자가 정의해준 Group 이 겹치치 않도록 Valid 셋을 분리하는 방식입니다.

# 데이터 생성
n_samples = 10
xs, ys = datasets.make_classification(n_samples=n_samples, n_features=5, n_classes=2)
print(f"data shape: xs={xs.shape}, ys={ys.shape}")
data_group = [1, 1, 1, 2, 2, 2, 3, 3, 3, 3]
# Cross Validation Methods
cvs = [
model_selection.GroupKFold(n_splits=3)
]
for cv in cvs:
print(f"\nCross Valid: {cv}")
for idx_train, idx_valid in cv.split(xs, ys, groups=data_group):
print(f"idx: train: {idx_train}, valid: {idx_valid}")
train_xs, train_ys = xs[idx_train], ys[idx_train]
valid_xs, valid_ys = xs[idx_valid], ys[idx_valid]
print(f"train shape: train_xs={train_xs.shape}, train_ys={train_ys.shape}")
print(f"valid shape: valid_xs={valid_xs.shape}, valid_ys={valid_ys.shape}")
data shape: xs=(10, 5), ys=(10,)
Cross Valid: GroupKFold(n_splits=3)
idx: train: [0 1 2 3 4 5], valid: [6 7 8 9]
train shape: train_xs=(6, 5), train_ys=(6,)
valid shape: valid_xs=(4, 5), valid_ys=(4,)
idx: train: [0 1 2 6 7 8 9], valid: [3 4 5]
train shape: train_xs=(7, 5), train_ys=(7,)
valid shape: valid_xs=(3, 5), valid_ys=(3,)
idx: train: [3 4 5 6 7 8 9], valid: [0 1 2]
train shape: train_xs=(7, 5), train_ys=(7,)
valid shape: valid_xs=(3, 5), valid_ys=(3,)
ShuffleSplit#
ShuffleSplit은 K-Fold 방법은 훌륭한 대안이 될 수 있습니다. Class 또는 Group 에 상관없이 주어진 사이즈 만큼 랜덤하게 Valid 셋을 분리합니다.
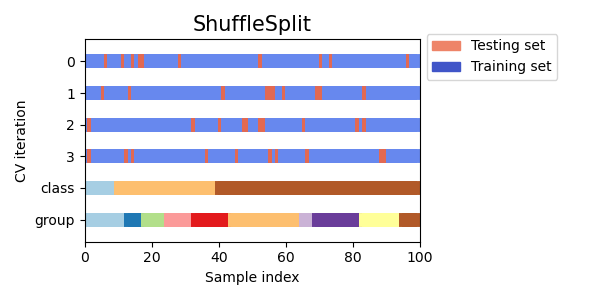
# 데이터 생성
n_samples = 10
xs, ys = datasets.make_classification(n_samples=n_samples, n_features=5, n_classes=2)
print(f"data shape: xs={xs.shape}, ys={ys.shape}")
# Cross Validation Methods
cvs = [
model_selection.ShuffleSplit(n_splits=3, test_size=0.25)
]
for cv in cvs:
print(f"\nCross Valid: {cv}")
for idx_train, idx_valid in cv.split(xs):
print(f"idx: train: {idx_train}, valid: {idx_valid}")
train_xs, train_ys = xs[idx_train], ys[idx_train]
valid_xs, valid_ys = xs[idx_valid], ys[idx_valid]
print(f"train shape: train_xs={train_xs.shape}, train_ys={train_ys.shape}")
print(f"valid shape: valid_xs={valid_xs.shape}, valid_ys={valid_ys.shape}")
data shape: xs=(10, 5), ys=(10,)
Cross Valid: ShuffleSplit(n_splits=3, random_state=None, test_size=0.25, train_size=None)
idx: train: [3 6 7 4 2 1 5], valid: [8 0 9]
train shape: train_xs=(7, 5), train_ys=(7,)
valid shape: valid_xs=(3, 5), valid_ys=(3,)
idx: train: [7 9 6 1 8 3 0], valid: [4 2 5]
train shape: train_xs=(7, 5), train_ys=(7,)
valid shape: valid_xs=(3, 5), valid_ys=(3,)
idx: train: [5 9 8 3 7 0 1], valid: [4 6 2]
train shape: train_xs=(7, 5), train_ys=(7,)
valid shape: valid_xs=(3, 5), valid_ys=(3,)
Stratified Shuffle Split#
Class의 비율로 주어진 사이즈대로 랜덤하게 Valid 셋을 분리합니다.
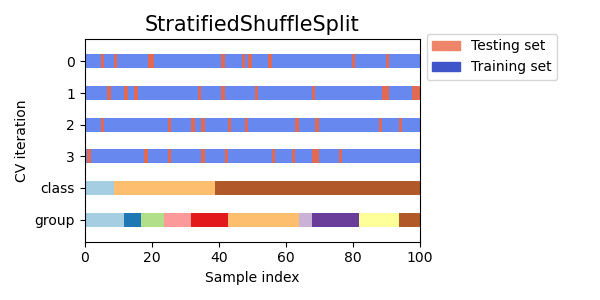
# 데이터 생성
n_samples = 10
xs, ys = datasets.make_classification(n_samples=n_samples, n_features=5, n_classes=2)
print(f"data shape: xs={xs.shape}, ys={ys.shape}")
# Cross Validation Methods
cvs = [
model_selection.StratifiedShuffleSplit(n_splits=2, test_size=0.25)
]
for cv in cvs:
print(f"\nCross Valid: {cv}")
for idx_train, idx_valid in cv.split(xs, ys):
print(f"idx: train: {idx_train}, valid: {idx_valid}")
train_xs, train_ys = xs[idx_train], ys[idx_train]
valid_xs, valid_ys = xs[idx_valid], ys[idx_valid]
print(f"train shape: train_xs={train_xs.shape}, train_ys={train_ys.shape}")
print(f"valid shape: valid_xs={valid_xs.shape}, valid_ys={valid_ys.shape}")
data shape: xs=(10, 5), ys=(10,)
Cross Valid: StratifiedShuffleSplit(n_splits=2, random_state=None, test_size=0.25,
train_size=None)
idx: train: [6 7 4 2 5 0 8], valid: [9 1 3]
train shape: train_xs=(7, 5), train_ys=(7,)
valid shape: valid_xs=(3, 5), valid_ys=(3,)
idx: train: [4 3 8 7 5 6 9], valid: [2 0 1]
train shape: train_xs=(7, 5), train_ys=(7,)
valid shape: valid_xs=(3, 5), valid_ys=(3,)
Group Shuffle Split¶#
Group의 비율로 주어진 사이즈대로 랜덤하게 Valid 셋을 분리합니다.
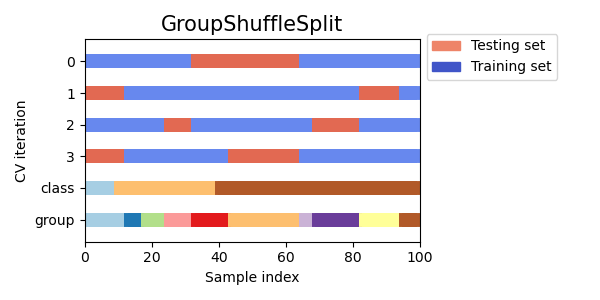
# 데이터 생성
n_samples = 10
xs, ys = datasets.make_classification(n_samples=n_samples, n_features=5, n_classes=2)
print(f"data shape: xs={xs.shape}, ys={ys.shape}")
data_group = [1, 1, 1, 2, 2, 2, 3, 3, 3, 3]
# Cross Validation Methods
cvs = [
model_selection.GroupShuffleSplit(n_splits=3, test_size=0.25)
]
for cv in cvs:
print(f"\nCross Valid: {cv}")
for idx_train, idx_valid in cv.split(xs, ys, groups=data_group):
print(f"idx: train: {idx_train}, valid: {idx_valid}")
train_xs, train_ys = xs[idx_train], ys[idx_train]
valid_xs, valid_ys = xs[idx_valid], ys[idx_valid]
print(f"train shape: train_xs={train_xs.shape}, train_ys={train_ys.shape}")
print(f"valid shape: valid_xs={valid_xs.shape}, valid_ys={valid_ys.shape}")
data shape: xs=(10, 5), ys=(10,)
Cross Valid: GroupShuffleSplit(n_splits=3, random_state=None, test_size=0.25,
train_size=None)
idx: train: [0 1 2 6 7 8 9], valid: [3 4 5]
train shape: train_xs=(7, 5), train_ys=(7,)
valid shape: valid_xs=(3, 5), valid_ys=(3,)
idx: train: [0 1 2 6 7 8 9], valid: [3 4 5]
train shape: train_xs=(7, 5), train_ys=(7,)
valid shape: valid_xs=(3, 5), valid_ys=(3,)
idx: train: [3 4 5 6 7 8 9], valid: [0 1 2]
train shape: train_xs=(7, 5), train_ys=(7,)
valid shape: valid_xs=(3, 5), valid_ys=(3,)